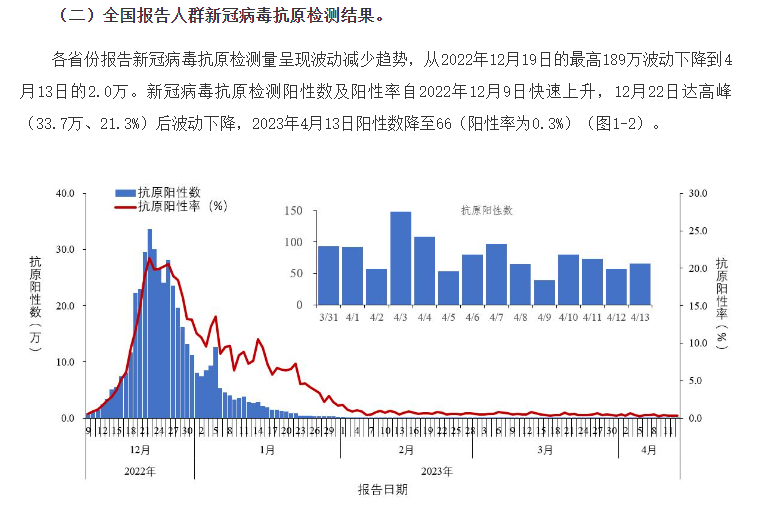
背景
用于生成抗体先导候选物的最常用技术之一是体外展示方法。在此,使用适当的文库来选择具有治疗应用所需特性的抗体。在选择活动期间,应用选择性压力或目标集中技术。
最近的一项研究表明,配备连续体外噬菌体和酵母展示的抗体库可以识别具有理想结合亲和力和可开发特性的药物样先导化合物。该文库在不到一个月的时间里成功鉴定出了 31 种抗严重急性呼吸综合征冠状病毒 2 (SARS-CoV-2) 的抗体。一些抗体表现出中和活病毒的能力,具有高亲和力和出色的生物物理特性。
尽管菌落挑取是在相对较短的时间内选择治疗性抗体候选物的有效方法,但它与选择过程中对更丰富克隆的固有偏见相关。高通量采摘活动很少通过克隆优势进行处理。
NGS 方法揭示了多样性和测序深度之间的非线性关联。该技术表明,在选择活动中,需要更大量的测序读数才能获得边际多样性收益。
重要的是要了解多样性增加的真实程度,而不是测序错误的结果。同样,必须考虑 NGS 启发法、计算工具和机器学习 (ML) 是否可以区分功能性克隆和人工克隆。
长读长测序克服了早期 NGS 平台基于单域或互补决定区 (CDR) 短读长的传统局限性。ML 已用于抗体发现和分子工程,在此期间,研究人员使用该技术从计算机文库中预测抗原结合物,阐明 B 细胞受体 (BCR) 的重要功能表示,以及识别可开发特性的分子结构。
机器学习应用有两种方法,包括监督方法和无监督方法。ML 算法的开发是为了最大限度地减少预测标签或值的损失,从而能够准确预测实验数据。
关于该研究
当前的研究评估了机器学习方法和启发式是否可以应用于体外发现活动产生的 NGS 数据集,以帮助确定抗体发现的先导优先顺序。当前的研究解决了有关在发现活动中使用 NGS 的一些重要问题。
所有问题均基于 SARS-CoV-2 感染的背景。这项研究的主要目的是确定适用于所有选拔活动的广泛原则。
研究结果
使用单链可变片段 (scFv) Gen3 半合成文库平台针对 SARS-CoV-2 的 S1 单体和受体结合域 (RBD) 进行了总共三轮筛选活动。使用两轮噬菌体 scFv 的生物素化蛋白质选择抗体,然后进行酵母展示。选择与所有三个靶标结合的蛋白质,并使用 5' 和 3' 内联 NGS 条形码进行 NGS。
分析了三种靶抗原的两种抗原浓度。此外,使用桑格测序对基于三个靶标的一个纳摩尔 (nM) 分选群体的随机集落进行测序。
研究人员探讨了 NGS 鉴定的克隆丰度是否与随机筛选结果相关。选择输出遵循幂律;如果将 NGS 得出的频率视为基本事实,则桑格克隆必须出现在 NGS 群体中的频率上限。NGS 克隆丰度也与随机筛选高度相关。
将 NGS 纳入发现活动中,能够分离出 30 多种亲和力低于 100 pM 的抗体。在 NGS 鉴定的表位多样性中观察到更大的表位多样性,从而强调了 NGS 在发现活动期间鉴定与结合亲和力和表位多样性相关的抗体特性的重要性。
估计获得所需抗体多样性所需的读数数量。例如,在以 10 nM 和 1 nM 亲和力重复选择三个靶标后,如果需要 1,000 个独特的 HCDR3,则每个靶标群体需要 215-402,000 个序列读取。
相对丰度和倍数富集可用于区分结合抗体和非结合抗体。当按照单个 10 至 1 nM 选择性步骤分析抗体时,发现亲和力、丰度和富集之间存在弱至中度关联。
当前的研究提出了一种简单的方法,通过为每个簇选择顶部克隆来识别群体中的抗体。这使得能够根据互补位多样性来分离结合物,并最大限度地减少异常序列的数量。机器学习算法用于将抗体分类为结合剂或非结合剂,并增强与亲和力的相关性。
AbXtract 模块中的 AbScan 是根据氨基酸化学特性开发的,用于无偏聚类方法。
结论
当前的研究强调了 NGS 在抗体发现方面的优势。NGS 数据有利于将选定的抗体分配给 HCDR3 簇,因为这种方法提供了额外的表位和互补位多样性。因此,NGS 数据可以为有效的治疗性抗体发现提供重要的见解和建议。
猜你喜欢
相关文章

抖音上血液科王鹤医生可靠吗?治疗的好吗?
抖音上血液科王鹤医生可靠吗?治疗的好吗?抖音上王鹤医生可靠吗?治疗的好吗?长期遭受血液疾病困扰的患者对来说,大家都希望有一位经验丰富经历深厚的...

去除车内空调异味的方法
去除车内空调异味的方法 冬季汽车经常会开暖风气温,但是长时间的开房汽车内空调就会产生难闻的气味,在处理空调气味的情况上,很多车主是比较头...

一地卫健委明确:关于基层医生的养老问题,解决办法来了!
乡村医生的养老问题,一直是基层医疗备受关注的问题。 贵州省卫健委针对《关于出台省级乡村医生相关政策和机制解决养老保险的建议》的答复显示,...

美最新研究:粒线体移植(MTx)可改善心脏骤停大鼠的存活率与神经恢复!
当心脏停止跳动时,流向大脑及其他器官的血流也会终止,并产生缺氧情形。而大脑在血流不足、并开始产生损伤前有约 4 分钟左右的急救窗口;缺血 10 ...

事发上海!一男医生将一女护士掐死,更多细节曝光
据悉,在上海医生和护士组合的家庭越来越少!4月3日中午,上海市公安局闵行分局官方微博发布信息:2023年4月1日10时50分,新龙路某小区内发生一起刑事案...